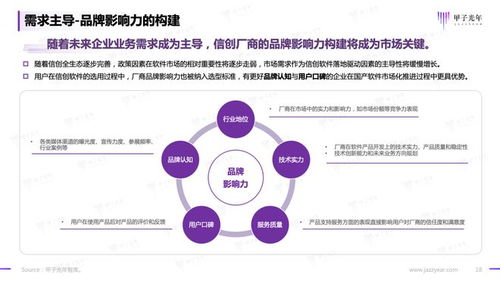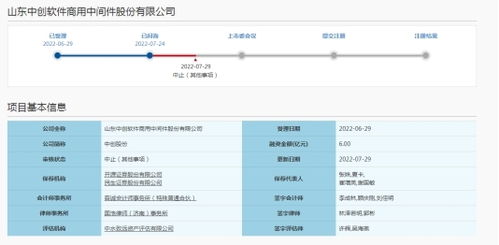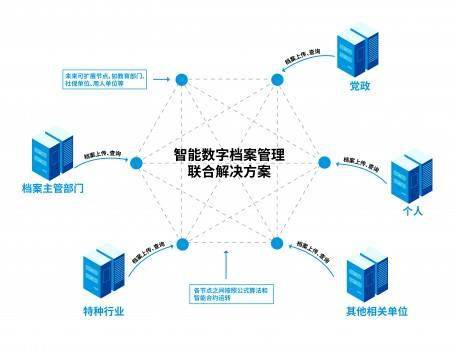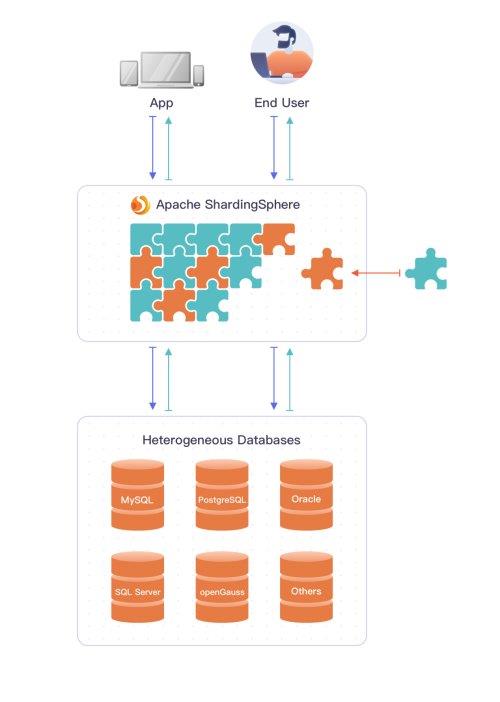
Volcano是一个专为高性能计算、人工智能和大数据工作负载设计的开源批处理系统,它构建在Kubernetes之上,为分布式计算提供了强大的任务调度和管理能力。随着企业对大规模计算需求的不断增长,Volcano作为基础软件服务,正逐渐成为云计算和容器化环境中的关键组件。
Volcano的核心功能与优势
Volcano通过优化资源调度,支持多种工作负载类型,包括机器学习训练、科学模拟和数据分析任务。其主要功能包括:
- 高级调度策略:支持公平共享、队列管理和优先级调度,确保资源在多个用户或任务间合理分配。
- 任务依赖管理:能够处理复杂的任务依赖关系,例如在流水线作业中,自动触发后续任务。
- 资源弹性扩展:与Kubernetes无缝集成,可根据负载动态调整资源,提高集群利用率。
- 容错与恢复:提供任务重试和故障恢复机制,确保长时间运行作业的可靠性。
这些特性使Volcano在AI训练、基因测序和金融建模等领域表现出色,帮助企业降低运维成本,提升计算效率。
Volcano的应用场景
在实际应用中,Volcano被广泛用于以下场景:
- 人工智能与机器学习:在大规模模型训练中,Volcano可以调度数百个GPU节点,优化训练时间。
- 大数据处理:支持Apache Spark、Flink等框架,实现高效的数据批处理作业。
- 科学计算:适用于气候模拟、物理实验等需要大量计算资源的科研项目。
部署与使用指南
部署Volcano相对简单,可以通过Helm chart或YAML文件在Kubernetes集群中快速安装。用户只需定义作业规范,例如指定资源需求、任务依赖和调度策略,即可启动批处理作业。Volcano社区提供了丰富的文档和示例,帮助用户快速上手。
未来展望
随着云原生技术的普及,Volcano作为基础软件服务,将继续演进,融入更多智能调度算法和跨云支持。它不仅提升了计算任务的效率,还为构建可扩展的分布式系统奠定了基础。对于追求高性能计算的企业来说,Volcano是一个值得投资的关键工具。
Volcano基础软件服务通过其强大的调度能力和灵活性,正在推动大规模计算任务的现代化进程,为用户提供稳定、高效的运行环境。